

This project deals with the recognition of toy objects which are arranged in scenes, such that they occlude each other up to 70%; see the figure (left).

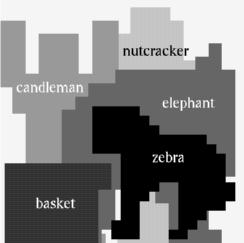
Figure: A scene with five objects occluding each other. Left: The original image. Superimposed are the graphs of the basket and the nutcracker. Nodes considered visible are black, those considered occluded are white. Right: The scene is interpreted by the system under the assumption that all objects in the scene are known.
Each toy object is represented by a labeled graph. The nodes are additionally labeled with binary variables indicating whether a node is considered to be visible or occluded. Here it is particularly advantageous that the graph structure permits referring to local subregions of the object. For finding the most promising locations for each model graph, we apply our standard elastic graph matching without local distortions. The goal of the system is then to find for each graph coherent regions of high similarity, considered as being visible, and other regions of low similarity, considered as being occluded. Based on the size and average similarity of the visible region it is decided whether the object is present in the scene or not. If all objects in the scene are known (but it is not known which objects are in the scene), the system can take additional information from the constraints that objects have an order in-depth and that at each image location only one object may be visible.
We have tested the system with a gallery of 13 toy objects on 30 scenes with 3 to 6 objects each and a total of 121 objects to recognize. The system recognized 97% of the objects correctly, and it determined all but three depth relations successfully.