

Conventional neural nets have a fast activity dynamics and synaptic weights which are subject to slow adaptation, i.e. learning. Since the time constants are so different, the activity dynamics can be treated as being independent of the synaptic adaptation. Christoph von der Malsburg has enriched this classical pradigm by the concepts of temporal correlations and fast synaptic modification based on these correlations [Mal81]. Correlations allow expressing relations between signals within a net. Neurons which process related information fire synchronously while other neurons fire uncorrelated. This is a solution to the binding problem. The fast switching synapses, or dynamic links, allow reconfiguration of the net architecture on a fast time scale during processing a signal. This synaptic reconfiguration is part of the signal processing and not to be confused with learning.
The most prominent application of these concepts is dynamic link matching (DLM). DLM is used for translation invariant object recognition. Objects are stored as labeled graphs represented by layers of neurons. In the case of face recognition, each model face is represented by a 10x10 layer of neurons; each neuron has attached a jet. The image is also represented by a neural layer, but of larger size (16x17). The image may have a face in any position. The task of DLM is to find the correspondences between the model faces and the face in the image, i.e. connecting the left eyes of the model faces with the left eye in the image, etc. This process is supposed to take place on a fast time scale and is part of the recognition process, in contrast to conventional neural nets where the connections are fixed during recognition. DLM provides translation invariance and robustness against distortions, e.g. due to rotation in depth. It would also provide invariance under rotation in the image plane, but the jets are not rotation invariant. Once DLM has found the correct mapping between models and image, recognition can easily be performed by comparing jets of connected neurons.
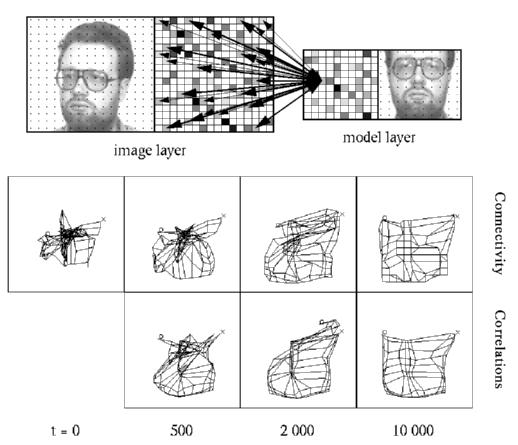
Figure: Dynamic link matching between an image and a sinlge model. Top: The image is on the left and a model on the right; the black dots indicate the neurons. Both layers are also shown in the middle with different jets indicated by different grey values. The arrows show the mutual connectivity as initialized with the similarities between the jets of connected neurons: strong connections between similar neurons and weak connections between dissimilar neurons. Bottom: Connectivity and correlations developing over time. The net display summarizes the four dimensional connectivity matrix. The image serves as a canvas on which the model is drawn as a net. Each node corresponds to a neuron; nodes of neighboring neurons are connected by an edge. The locations of the nodes correspond to the center of their projective field. The correlations can be displayed in the same way by taking the correlations instead of the synaptic weights. One can see, that connectivity as well as correlations improve over time, the correlations being in general cleaner than the connectivity; see also Movie 1.
Movie 1 (350 kB): Connectivity (top) and correlations (bottom) developing over time between t=0 and t=4000.
For inducing the correlations we employ a layer dynamics generating a running blob of activity. The blobs on the image and model layers synchronize due to interaction via the connectivity matrix, which is initialized by the jet similarities. The induced correlations then modify the weights to generate the final mapping. Since the image layer is larger than the model layers, we have introduced an attention blob, which is larger than the running blobs and restricts its mobility. It has no active motion but is itself pushed by the running blob. By this means the attention blob slowly moves onto the correct face position in the image; see Movie 2. Without attention blob, the running blobs would not be able to sychronize with each other; see Movie 3.
Movie 2 (336 kB): Running blobs (black) and attention blob (blue) on the image layer (top) and model layer (bottom). The red tails behind the running blobs indicate selfinhibition pushing the running blobs forward. The smaller square within the image indicates the correct face position.
Movie 3 (196 kB): Same as Movie 2 but without attention blob.
Remark: Even though this system has some nice features and may be conceptionally appealing, it also has some serious flaws. It has been shown that comparable recognition rates can be achieved by a much simpler matching method [Wis99a]. I see three possible improvements of the current system. First of all, the input into a layer and not the activity of a layer should be used as a recognition signal. The activity of a layer is subject to too much noise. Second of all, the matching should only be done with the average or rather maximum connectivity matrix, which corresponds to matching with a face bunch graph. Third of all, the weight dynamics should be modified as suggested in [WisSej98a]. This would realize a clearer cut between topographical constraints and the objective of feature similarity. Another problem of this system is that it is so slow. Experiments have shown that humans are able to recognize objects within about 150 ms. This is far too fast for the system presented here. I am therefore working on an alternative model of translation invariant object recognition which is based on pure feed-forward processing; see the project Unsupervised Learning of Invariances. However, I think this DLM-model has potential for processes where time is not such a constraint. My favored idea is that DLM can play an important role in structuring memory, e.g. finding structural similarities between stored information during sleep. (Laurenz Wiskott)